
For the longest time, Regex has been similar to black magic in my mind. I’ve seen these expressions used by (scripting) wizard to do amazing things, but I have never been able to wrap my head around them.
The best I’d managed in the past was to Google a pattern that matched what I was looking for and stole re-purposed them in my scripts without much understanding of how or why it actually worked.
For example, let’s say I was trying to ensure that input was a valid NetBIOS name. I’d head off to Google and search for “NetBIOS name regex” and likely end up grabbing something from the first Stack Overflow result. I would then blindly drop that into my script.
$Input -match "^[\\w!@#$%^()\\-'{}\\.~]{1,15}$"
This would work, nine times out of ten, and I’d happily go on my merry way.
Lately I’ve been trying to make a concerted effort to actually learn Regex, understand what the expressions are actually doing… and even occasionally writing my own.
Still Needing a Little Help
Don’t get me wrong, I’m not writing my expressions without any sort of references or help.
I’m particularly partial to the site RegExr.
This site allows you to easily test expressions against some given text (which you can add your own test data to.) It also has a handy reference on the left hand side where you can see character classes, anchors, quantifiers, and more. Each item has a write up and an example so you should be able to find all the components you need.
Somebody Mentioned Normalizing Phone Numbers?
I recently went through and normalized all of the cellphone numbers in an Active Directory. Specifically I was changing them into an international format (with spaces for readability) from a local format without any spaces.
Before we get in to the example, I’m from New Zealand and will be working with New Zealand’s cellphone standard. I imagine numbers overseas may be longer and formatted differently, but it’s the concepts that matter not the finished example right?
The source numbers were coming in format of 0271112222 and it’s possible for a cellphone number in NZ to be a digit longer or shorter than this. It’s also possible that the leading zero may be missing. All cellphone numbers’ first none zero digit is a 2 (unless they’ve slipped into using another digit without me noticing.)
These numbers needed to be changed to their international format, +64 27 111 2222. The +64 being the country code, the 27 being the original mobile carrier, and the remainder being the individual number proper.
Before using regex I probably would have tackled this task with a complex series of if statements and string manipulation methods which as inserting characters in at specific indexes.
Regex to the Rescue
Let’s talk through each step of this. First I’ll consult RegExr and find a token that will match against a number. It turns out that I can use \d which matches any digit. If you’ve ever seen regex notation with square brackets listing out characters and digits, this is the equivalent of [0-9].
I want to start be matching what will be my leading 2 and the following digit, to do this I’ll use the following:
(2\d)
That is to say, I want to match a two and any other single digit. In my example number this will match against the 27.
Now I need the next three digits. I could list out three instances of the digit token:
(\d\d\d)
That really doesn’t scale though, does it? Instead we can use a quantifier to specify how many digits we’re wanting. Do this by putting the number of digits in curly braces.
(\d{3})
Excellent, when used in conjunction with the previous part of the expression, this will match against the 111 in the example number.
Finally we need the last set of digits. This one though is four digits in the example number, but when I’m actually using this it could be as few as three digits or as high as five.
It turns out our new friend the quantifier can actually specify a minimum and maximum number of times to match.
(\d{3,5}
This will match the 2222 in my example number, but could equally match against 222 or 22222.
Putting this all together we end up with this expression:
(2\d)(\d{3})(\d{3,4})
If I throw this into RegExr with some sample numbers in the text field I can see that it matches my example number but not the numbers below it. One of them didn’t match because it had a leading 3 instead of a 2 and the other was simply too short.
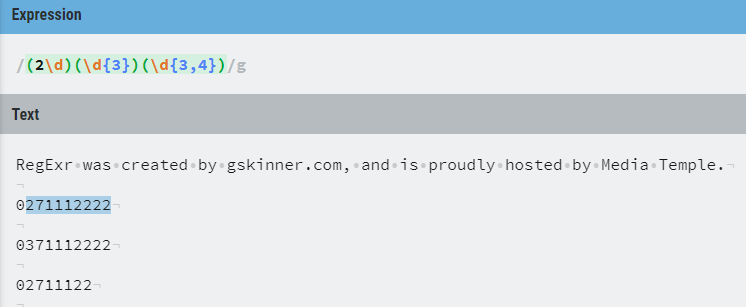
RegEx test using RegExr
That’s all well and good, but we’re trying to make changes here right?
Those Brackets Are There on Purpose
Strictly speaking, the expression we built works perfectly fine without the brackets (i.e. 2\d\d{3}\d{3,4}) when it comes to finding my example number. But those brackets weren’t there just as a stylistic decision or to chunk it up into logical units for the purpose of demonstration.
The brackets denote a capturing group, and you’re able to actually reference these to as sub-strings.
In PowerShell this manifests itself when using the -Replace operator. Each capturing group can be reference in turn using special tokens starting at $1 and incrementing with each group.
So, let’s just go ahead and test this out in PowerShell, using our expression against the test number.
'0271112222' -Replace '(2\d)(\d{3})(\d{3,4})', '+64 $1 $2 $3'
Run that and we get the output: 0+64 27 111 2222
Yes! Awesome! Wait…
I Goofed
While the bulk of the formatting there is right, I didn’t account for leading zero. We could use another capturing group and just not reference it in the replacement string, but I think I’d rather get fancy and use a NON-capturing group. These are similar to the normal groups, except that you include ?: as the first two character inside the brackets.
'0271112222' -Replace '(?:0)(2\d)(\d{3})(\d{3,4})', '+64 $1 $2 $3'
Now we can celebrate, we’ve officially got the output we need (+64 27 111 2222)!
There’s one other scenario I want to quickly cover off, and that’s internationalizing cellphone numbers that may already have spaces. I’ll repeat the use of non capturing groups, using the whitespace token \s, and the star quantifier * which simply means it’s match zero or more times (so that the lack of any whitespace won’t cause issues.)
This makes my final expression look like this:
(?:0)(2\d)(?:\s)*(\d{3})(?:\s)*(\d{3,4})
Fair enough, that may still look a little complex if you’re new to regex but I hope that having built it up step by step it can be deciphered.
Also, if you’re a regex guru be gentle. There’s probably much better ways to do this, but this is the result of my exploration so far.
Next Steps
I’m going to go off and read a book on regex now (and watch some videos), as they have finally “clicked” for me and I now have that seed which is spurring me on to learn more. It’s better to ride that wave of inspiration, especially when it’s heading towards something useful, than ignore it!
Have you done anything interesting with regex lately, or are beginning to realize that you probably could have saved some time by using one instead of brute forcing some string manipulation? Let me know!